
The vulnerability scanner who cried wolf – False positives in SCA-Tools
2022-06-02
3 min

The problem of false positives in security scanners or, more specifically software composition analysis (SCA) tools, has been debated numerous times (for example here, and here). Despite this issue being well known, and a huge pain point for any developer working with security, there’s still no apparent solution. Most likely because it’s a tricky problem to fix.
Trying to find out what is a real threat and what is a false positive can be an annoying and time-consuming task. There may be a vulnerability, but the vulnerability might not be relevant to your code at all. After a certain number of false alarms you probably stop paying attention, and this is where the real danger begins – before you know it, you’re in trouble.
Debricked’s RnD team has been scratching their heads over this problem for years. Just a few months ago they finally started coming close to a solution.
Introducing Vulnerable Functionality
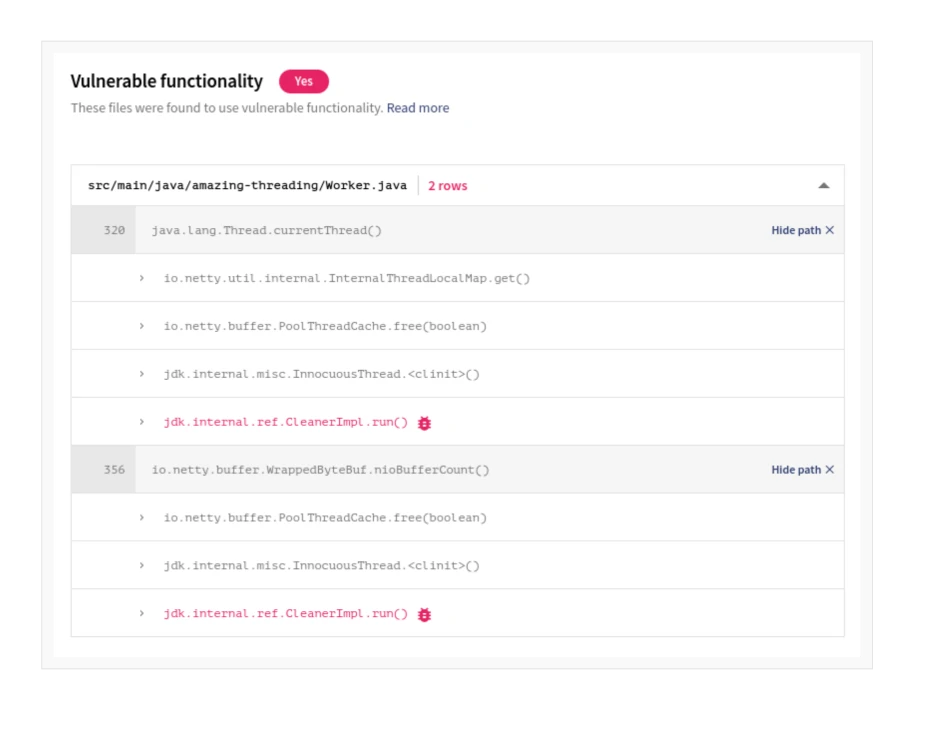
This new feature, which we call Vulnerable Functionality, allows us to, first, identify which method, or class, is actually vulnerable. Secondly, it analyses your code to determine if these methods or classes are currently being used.
So, what does this mean for you?
Identifying the vulnerable functionality allows us to deliver fewer, more accurate vulnerability alerts that are actually contextualized to your code.
Essentially, it eliminates false positives where you are using a vulnerable dependency, but not the vulnerable part – meaning that it’s safe for you to continue using it for now. We also alert you if, or when, that changes.
As of today, we offer this for Java with Github Actions, with more support to come during the year.
Identifying the vulnerable functionality
Now, how does this work in practice?
At first glance this seems simple; just search through your code to see if it calls any vulnerable code. However, this type of analysis doesn’t take transitive function calls into account, which makes it less powerful. After careful consideration, the RnD team decided it simply wasn’t enough. Instead, our solution creates a call graph, which includes all function calls, including transitive ones.
To find the vulnerable open source code for a particular vulnerability, we use a combination of git, machine learning and Abstract Syntax Trees (AST). An AST is a way to represent code, which extracts the vital information of what classes, functions, and methods exist for a particular project and on what rows they are declared. The AST is built for the secure and vulnerable code version and we check what changed between those versions.
So, let’s say we have a vulnerability in a package that was fixed in version 1.3.4. To find the vulnerable functions, we look at what functions changed between 1.3.3 and 1.3.4 and estimate that somewhere in that change, the vulnerability was fixed.
There are of course challenges with this approach as sometimes vulnerabilities are fixed in major releases (3.9 -> 4.0, or 1.2.4 -> 1.3.0) which typically include a ton of changes to the codebase. Luckily, we can often find the actual pull request or commit that fixed the vulnerability. This is done using some clever machine learning, which significantly increases our accuracy.
Great! Now we know what functions are vulnerable for a particular open source vulnerability. The next step is to find out if you are calling that vulnerability in your codebase. To figure this out, we build a Call Graph from your application and the open source you are using. This allows us to find the relations between functions in your code and the open source software you are using, including which functions call each other and how.
What this means is that we can filter out vulnerabilities that aren’t vulnerable to you. Therefore, giving you fewer alerts to assess and allowing you to trust that when we cry wolf, the wolf is probably in your rear-view mirror.
A look into the future
Despite this being a massive step in the right direction, identifying the vulnerable functionality is of course not the be-all and end-all solution to reduce noise in SCA tools. But we have more things brewing that has the potential to bring us even closer to our goal.
This feature is currently available in our free tier. Do note however that it is in a beta state and currently under development. It also takes a bit of setup to enable, so make sure to check out our docs. Regardless of if it’s a hit or a miss, we would love to hear your feedback.



