
How to scale Symfony consumers using Kubernetes

2020-02-04
4 min
At Debricked we have been using Symfony for our web backend for a while now. It has served us very well and when they announced the Messenger component back in Symfony 4.1, we were eager to try it out. Since then we have used the component for asynchronous queuing emails.
Lately, the need arose to separate our handling of GitHub events, which we receive from our GitHub integration, from the web backend to a separate microservice for performance reasons. We decided to utilise the producer/consumer pattern which the Messenger component provides as it lets us asynchronously dispatch the various events to a queue and then immediately acknowledge the event to GitHub.
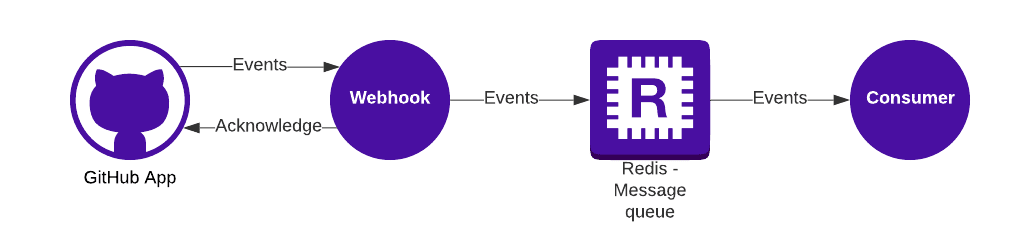
However, compared to sending emails, handling some GitHub events can be time consuming. We also have no control of when these events will happen, so the load is both unpredictable and irregular – we needed auto scaling of our consumers.
Kubernetes Autoscaling to the rescue
As we already had most of our infrastructure deployed to Kubernetes on Google Cloud, it made sense to try to utilise that for our consumers. Kubernetes offers something called Horizontal Pod Autoscaler, which lets you automatically scale your pods up and down depending on some metric.
The autoscaler has one metric built in, the CPU metric. It lets us set a target CPU load across our pods and then Kubernetes will automatically adjust the amount of pods to match the target. We will use this metric to make sure we always have a reasonable amount of pods, running our consumers, available.
Preparing Docker image running consumers
Concluding that Kubernetes could help us out we now need a suitable Docker image for our pods to run. We base our consumer image on our base image, which is based on Debian and contains our backend logic, including the logic for the GitHub event consumer/message handler.
Symfony recommends a tool called “Supervisor” for controlling the execution of the consumer, hence we add this to our image and starts it in Docker’s CMD directive, see example code below:
FROM your-registry.com:5555/your_base_image:latest USER root WORKDIR /app RUN apt update && apt install -y supervisor # Cleanup RUN rm -rf /var/lib/apt/lists/* && apt clean COPY ./pre_stop.sh /pre_stop.sh COPY ./supervisord_githubeventconsumer.conf /etc/supervisord.conf COPY ./supervisord_githubeventconsumer.sh /supervisord_githubeventconsumer.sh CMD supervisord -c /etc/supervisord.conf
If you look carefully we also add two files which are related to running Supervisor(d). The files looks like the following:
Config file
[supervisord] nodaemon=true user=root [program:consume-github-events] command=bash /supervisord_githubeventconsumer.sh directory=/app autostart=true # Restart on unexpected exit codes autorestart=unexpected # Expect 37 exit code, returned when stop file exists exitcodes=37 startretries=99999 startsecs=0 # Your user user=www-data killasgroup=true stopasgroup=true # Number of consumers to run. We use a high number because we are bound by network IO numprocs=70 process_name=%(program_name)s_%(process_num)02d stdout_logfile=/dev/stdout stdout_logfile_maxbytes=0 stderr_logfile=/dev/stderr stderr_logfile_maxbytes=0
Bash script
if [ -f "/tmp/debricked-stop-work.txt" ]; then rm -rf /tmp/debricked-stop-work.txt exit 37 else php bin/console messenger:consume -m 100 --time-limit=3600 --memory-limit=150M githubevents --env=prod fi
It is a fairly standard Supervisor config with a few items worthy of note. We are executing a bash script, which in turn either exits with code 37, more on that in next section, or executes the Messenger component’s consume command using our GitHub events consumer. We also configure Supervisor to automatically restart on unexpected failures, which is any status code not being 37.
In our case we will run a high number of consumers concurrently, 70, due to the load being very network IO bound. By running 70 consumers concurrently we are able to fully saturate our CPU. This is required for the Horizontal Pod Autoscaler’s CPU metric to work correctly, as the load would otherwise be too low – making the scaling being stuck at the minimum configured replicas, no matter how long the queue is.
Gracefully scale down pods/consumers
When the autoscaler decides the load is too high it starts new pods. Thanks to the asynchronous nature of the messenger component we do not need to worry about concurrency issues such as race conditions. It will just work out of the box with multiple consumers, hence the increased pods/consumers count won’t cause any issues, but what happens when the load is too low and the scaler decides to scale down the instance?
By default the autoscaler will just abruptly terminate a running pod if it decides it is not needed anymore. This causes a problem with the consumer as it might be in the middle of handling a message. We need a way of gracefully shutting down the pod, consuming the message we are currently dealing with and then exit.
In the previous section in the Dockerfile you might have noticed that we copied a file called `pre_stop.sh` to our image. That file looks as the following:
# Script to execute when pod is about to be terminated
touch /tmp/debricked-stop-work.txt
chown www-data:www-data /tmp/debricked-stop-work.txt
# Tell workers to stop
php bin/console messenger:stop-workers --env=prod
# Wait until file has been deleted
until [ ! -f /tmp/debricked-stop-work.txt ]
do
echo "Stop file still exists"
sleep 5
done
echo "Stop file found, exiting"
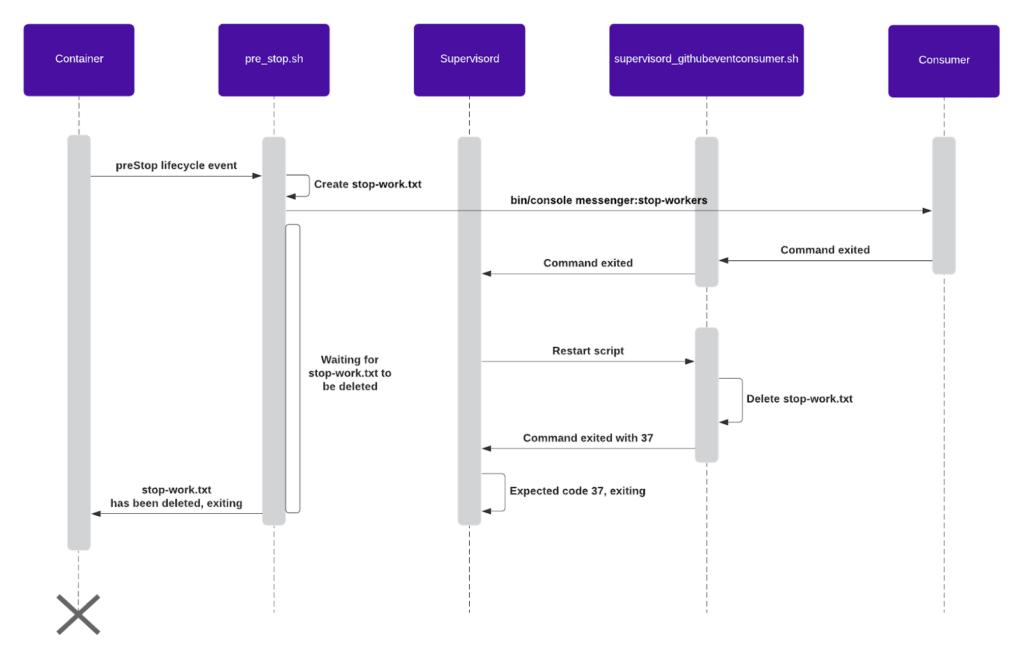
When executed, this bash script will create a `/tmp/debricked-stop-work.txt` file. Because the script also calls `php /app/bin/console messenger:stop-workers`, it will gracefully stop the current workers/consumers, causing the `supervisord_githubeventconsumer.sh` to be restarted by Supervisord. When the script it restarted it will now immediately exit with status code 37 because the `/tmp/debricked-stop-work.txt` exists. In turn causing Supervisor to exit, because 37 is our expected exit code.
As soon as Supervisor exits, so will our Docker image as Supervisor is our CMD and the `pre_script.sh` will also terminate because `supervisord_githubeventconsumer.sh` deletes the `/tmp/debricked-stop-work.txt` before exiting with 37. We have achieved a graceful shutdown!
But when is `pre_script.sh` executed? You might be asking yourself. We will execute it on Kubernetes container’s `PreStop` lifecycle event.
This event occurs whenever a container is about to be terminated, such as when being terminated by the auto scaler. It is a blocking event, meaning that the container will not be deleted before this script is complete, just what we want.
To configure the lifecycle event we just need to a few lines of code to our deployment config, like in the example below:
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: gheventconsumer
namespace: default
labels:
app: gheventconsumer
tier: backend
spec:
replicas: 1
selector:
matchLabels:
app: gheventconsumer
template:
metadata:
labels:
app: gheventconsumer
spec:
terminationGracePeriodSeconds: 240 # Consuming might be slow, allow for 4 minutes graceful shutdown
containers:
- name: gheventconsumer
image: your-registry.com:5555/your_base_image:latest
imagePullPolicy: Always
Lifecycle: # ← this let’s shut down gracefully
preStop:
exec:
command: ["bash", "/pre_stop.sh"]
resources:
requests:
cpu: 0.490m
memory: 6500Mi
---
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: gheventconsumer-hpa
namespace: default
labels:
app: gheventconsumer
tier: backend
spec:
scaleTargetRef:
kind: Deployment
name: gheventconsumer
apiVersion: apps/v1
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 60
Overwhelmed? Here is an image of the shutdown flow:
Conclusion
In this article, we have learnt how to dynamically scale Symfony Messenger consumers depending on load, including gracefully shutting them down. Resulting in high throughput of messages in a cost effective manner.



